Manuals
/
HP
/
Computer Equipment
/
Desktops
HP
8000 tower
manual
RAID 1 with two hard drives Mirror
Models:
8000 tower
1
10
29
29
Download
29 pages
22.5 Kb
7
8
9
10
11
12
13
14
Install
Configurations
Accessing RAID Option ROM
BIOS Interface
settings pass=offlineServicing
value 0=disabled 1=enabled
Page 10
Image 10
Page 9
Page 11
Page 10
Image 10
Page 9
Page 11
Contents
AHCI and RAID on
HP Compaq Elite 8000, 8100, 8200, and 8300 Business PCs
Intel Rapid Storage Technology
Intel chipset
Introduction
HP business PC
Chipset components
Acronym or term
Basics of AHCI and RAID Technology
Definitions
Description
BIOS Interface
BIOS / Software / Hardware Considerations
Benefits of AHCI
New operating system installation
?xml version=1.0 ?
settings pass=offlineServicing
PathAndCredentials DriverPaths component settings unattend
publicKeyToken=31bf3856ad364e35 language=neutral versionScope=nonSxS
Enhancing existing Windows XP images from IDE Mode
HKLM\System\CCS\Services\iaStor\Parameters\PortX nameGTF
value 0=disabled 1=enabled
GTF Support HP 8100 and 8200 Business PCs only
Changing AHCI to IDE Mode through the HP Replicated Setup Utility
Limitations
Basic RAID Types
Hardware
RAID 0 with three hard drives is shown in Figure
Figure 1 Performance - RAID 0 with two hard drives
Figure 2 Performance - RAID 0 with three hard drives
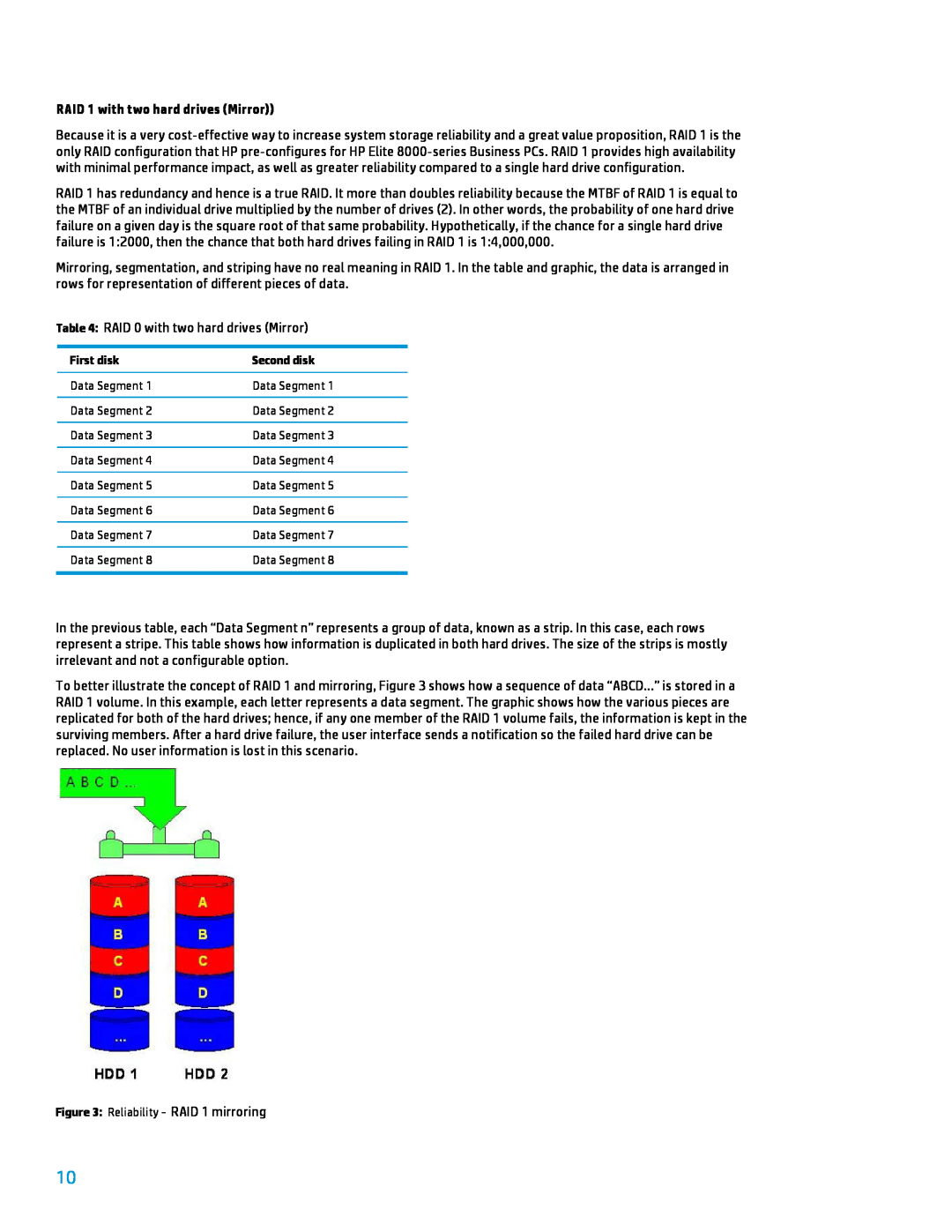
RAID 1 with two hard drives Mirror
RAID 5 with three hard drives
Intel Matrix RAID Technology
Configurations
Recommended configurations
Other supported configurations
Unsupported configurations
Configuring RAID on non-factory preinstalled configurations
Enabling RAID through F10 System BIOS
Accessing RAID Option ROM
Configuring RAID Volume using the Option ROM
4. Type Y to continue
Notes for operating system installation
Intel Rapid Storage Technology software installation
Using the Intel Rapid Storage Console interface to Configure RAID
RAID migrations using Intel Rapid Storage Console
Migration to RAID 1 from two non-RAID hard drives
Migration to RAID 0 from two non-RAID hard drives
Migration to RAID 0 from three non-RAID hard drives
Migration to RAID 5 from three non-RAID hard drives
Migration to Matrix RAID 5 and RAID 0 from three non-RAID hard drives
12. Reboot the system after the migration finishes. NOTE Back up all data before proceeding
Migration to Matrix RAID 1 and RAID 0 from two non-RAID hard drives
Configuring Intel Rapid Storage Console for
Email notifications HP Elite 8200 and 8300 Business PCs only
Installation
Abbreviation
Table 8 Language support
Language
Degradation
Get connected
hp.com/go/getconnected
Top
Page
Image
Contents