Citrix NetScaler Policy Configuration and Reference Guide
Citrix NetScaler
Copyright and Trademark Notice
Contents
Chapter
Contents
Converting Text to Hexadecimal Format
Citrix NetScaler Policy Configuration and Reference Guide
Contents Vii
Blocking Access to Inline Images
Accommodating Browser Dependent Content
Blocking Access by Robots
Reducing Web Server Redirects
Preface
About This Guide
Citrix NetScaler Policy Configuration and Reference Guide
Preface
New in This Release
Audience
Convention Meaning Boldface
Formatting Conventions
Formatting Conventions
To view the documentation
Getting Service and Support
Related Documentation
Documentation Feedback
To provide feedback from the Knowledge Center home
Introduction to Policies Expressions
Advanced and Classic Policies
Benefits of Using Advanced Policies
Basic Components of an Advanced or a Classic Policy
Chapter Introduction to Policies and Expressions
How Different NetScaler Features Use Policies
NetScaler Feature, Policy Type, and Policy Usage
DNS
Associated cache server
Authorization policies authorize users
Authorization
AAA Traffic Classic
About Actions and Profiles
Access Classic
Authorization policies, however, can be
Functions
Pre-Authentication. Uses
Use of Actions and Profiles in Different NetScaler Features
Feature Use of an Action Use of a Profile
Authorization. Uses Allow
About Policy Bindings
Server
About Evaluation Order of Policies
About Advanced Expressions
Advanced and Classic Expressions
Order of Evaluation Based on Traffic Flow
About Classic Expressions
Before You Proceed
Chapter
Citrix NetScaler Policy Configuration and Reference Guide
Configuring Advanced Policies
Argument Specifies
Creating or Modifying an Advanced Policy
Advanced-Policy Parameters
Policy Configuration Examples
Following is an example of a Rewrite policy and action
Binding Advanced Policies
Feature-Specific Differences in Policy Bindings
Feature-Specific Bindings for Advanced Policies
Provide rules for modifying
Policies Global default Responder function Policy label
NetScalers integrated
Address of the incoming
Bind Points and Order of Evaluation
Entries in a Policy Bank
Advanced Policy Evaluation Across Features
Chapter Configuring Advanced Policies
Optional
Evaluation Order Within a Policy Bank
Format of Each Entry in a Policy Bank
How Policy Evaluation Ends
Example
How Features Use Actions After Policy Evaluation
Binding a Policy Globally
Details pane, click Feature Name policy manager
Binding a Policy to a Virtual Server
Unbinding an Advanced Policy
Displaying Policy Bindings
Unbind responder global policyName
Creating Policy Labels
Creating a Policy Label
To create a policy label by using the configuration utility
Entries in a Policy Bank
Configuring a Policy Label or Virtual Server Policy Bank
Binding a Policy to a Policy Label
Attribute Description
Configuring a Policy Label
Example
Choices are Integrated Caching, Rewrite, or Responder
Configuring a Policy Bank for a Virtual Server
Configure Virtual Server dialog box click the Policies tab
Chapter Configuring Advanced Policies
At the NetScaler command prompt, for the Responder, type
Configuring and Binding Policies with the Policy Manager
Click Regenerate Priorities
To remove unused policies by using the Policy Manager
Citrix NetScaler Policy Configuration and Reference Guide
Configuring Advanced Expressions Getting Started
Expression Characteristics
Basic Elements of an Advanced Expression
Prefixes
Http.res.header.myheader
Single-Element Expressions
Feature Types of Expression Prefix Used in the Feature
Features Content Switching
Operations
Operation Determines whether or not
Basic Operations on Expression Prefixes
Basic Operations for Expressions
Basic Types of Operations
Configuring Advanced Expressions Getting Started
Compound Advanced Expressions
Compound Operations for Strings
Booleans in Compound Expressions
Parentheses in Compound Expressions
String-Based Operations for Compound Advanced Expressions
Logical operations on strings
Compound Operations for Numbers
Arithmetic Operations for Compound Advanced Expressions
Returns 12 binary
Num % num
Expression on the right
Result of applying the ~ operator is -11 a binary 1110011
Right-side number argument number of bits
Binary 1100 and numeric.expression2 returns 10 binary
Whole expression evaluates to 8 binary
Following example assumes that numeric.expression1 returns
Number .SUB
Number .ADD
Integer Value Following is an example
Integer Number value Following is an example
Number .LT
Number .LE
Integer Integer argument Following is an example
Binary value of 10 is 1010, and the result of applying
Expression as an argument rather than an integer
Result of applying the Bitneg operator is -11 a binary
1110011, 32 bits total with all ones to the left
Assumes that numeric.expression returns 12 binary
Another expression as an argument rather than an integer
Bitxor operator to the entire expression is 6 binary
Caret performs a similar function to BITXOR, but takes
Number.LSHIFT
Value represented by double
Number.RSHIFT
Double .ADDi
Parameters
Double .GTi
Double .GEi
Value represented by double is greater than or equal to
Value represented by double is greater than the argument
Configuring Advanced Expressions in a Policy
Classic Expressions in Advanced Expressions
Following is an example of configuring a caching policy
HTTP.REQ.BODY1000.BETWEENthis,that
Configuring Named Advanced Expressions
Click Advanced Expressions
Chapter
Citrix NetScaler Policy Configuration and Reference Guide
Advanced Expressions Evaluating Text
About Text Expressions
About Operations on Text
Chapter Advanced Expressions Evaluating Text
Compounding and Precedence in Text Expressions
Categories of Text Expressions
Guidelines for Text Expressions
Http Expression Prefixes that Return Text
Expression Prefixes for Text
Expression Prefixes for Text in Http Requests and Responses
Prefix Description
Returns incorrect results if the host name has an IP
Returns the domain name part of the host name. For
Myhost.com8080, the domain is myhost.com
Address. For information on expressions for IP
URL
LISTT,. IGNOREEMPTYELEMENTS.COUNT
LISTT,.COUNT
HTTP.REQ.USER.EXTERNALGROUPS
HTTP.REQ.USER.GROUPS
User belongs
Returns a list of internal groups to which the user
For example, the following expression returns a
HTTP.REQ.USER.INTERNALGROUPS
Group
Returns a portion of the Http response body.
Default value of 80 or 443 for Https connections
Returns the Http version listed in the request
Integer argument
Expression Prefixes for VPNs and Clientless
VPN and Clientless VPN Expression Prefixes that Return Text
VPN and Clientless VPN Description Expression
Evaluates the server portion of the host name
By default, is not considered an empty element
When evaluating this header
Extracts a slash- / separated list from the path
Delimiters from the query string in a URL
Extracts a name-value list, using the =
Evaluates the protocol in the URL
This method ignores the empty elements in a
Hostname
Has an empty element following a=10
Ignores empty elements in a list. For example, if
List delimiter is a comma , the following list
Evaluating this header
Element after a=10
Ignores empty elements in a name-value list. For
Example, the following list contains an empty
As another example, consider the following http
Following expression returns True
Results in Boolean True if the host name
Is case insensitive
Evaluates the server part of the host name
Entry a=10
This method ignores the empty elements in a list
For example, if the delimiter in a list is ,
Consider the following header
=11 is not considered an empty element
Example, the following list uses a semicolon
Preceding example, the element following
Evaluating the same header
Basic Operations on Text
Operations on Text
Basic Operations on Text
Returns a Boolean True value if the target contains
Operations on Case Sensitivity of Text
Operations for Calculating the Length of a String
Operations for Controlling Case Sensitivity
Basic Text Operation Description
Operations on Strings Based on a Character Count
Complex Operations on Text
Operations on the Length of a String
Case Operation Description
Character Count Operation Description
Operations on a Portion of a String
Basic Operations on a Portion of a String
Object of 0 length
Matches starting string, and if the suffix of the target
Returns a Boolean True value if the length of the text
Object is greater than or equal to the sum starting string
Matches ending string
Converting Text to a Hash Value
Operation Description
Applying the Base64 decoding algorithm. The operation
Operator Description
Base64 encoding algorithm
Raises an Undef if text is not in B64-encoded format
Converting Text to Hexadecimal Format
Citrix NetScaler Policy Configuration and Reference Guide
Advanced Expressions Working with Dates, Times, and Numbers
Format of Dates and Times in an Expression
Dates and Times in a Rewrite Action
Expressions for the NetScaler System Time
Expressions that Return NetScaler System Dates and Times
NetScaler Time Description Operation
Advanced Expressions Working with Dates, Times, and Numbers
Sys.time.leGMT 2006 True in this example
Scheduled reboot, and returns an integer
Is equal to the time argument
False depending on the current timezone
Expressions for SSL Certificate Dates
Time2
SSL Certificate Operation Description
True
You can specify the following evaluation results for
For example, if the current time is GMT 2005 May
10h 15m 30s, and it is the first Sunday of the month
This example are in parentheses
Returns a Boolean True if the time precedes or is
Closest boot time is in the past, the integer is
Extracts the last hour that the certificate is valid
Equal to the time argument
Extracts the last weekday that the certificate is valid
System time and the specified time and returns an
If it is in the future, the integer is positive
To give the weekday in the time value
Arguments must be fully specified
Returns a Boolean True if the time value is between
Time1, time2 arguments. Both the time1, time2
LOCAL, and time2 must be bigger than time1
Results are in parentheses
Returns a Boolean True if the time is greater than
After or equal to the time argument
Returns a Boolean True if the time occurs after
Returns the number of seconds between the current
Extracts the last minute that the certificate is valid
Returns the current month as an integer from
NetScaler system time and the specified time as an
6 Saturday
Extracts the last second that the certificate is valid
Returns the current second as an integer from 0 to
Element of time from time2, it is assumed to have
Expressions for Http Request and Response Dates
Prefixes That Evaluate Http Date Headers
111
Citrix NetScaler Policy Configuration and Reference Guide
Advanced Expressions Parsing HTTP, TCP, and UDP Data
About Evaluating Http and TCP Payload
About Evaluating the Payload Body
Expressions for Http Headers
115
Http Header Prefix Description
Prefixes for Http Headers
Prefixes That Extract Http Headers
Advanced Expressions Parsing HTTP, TCP, and UDP Data
First instance is returned
Returns the value of Path field of the cookie
As a slash- / separated list. Multiple
For example, the following is a cookie with
From Set-Cookie Customer =
Returns the value of Port field of the cookie
Operate as a comma-separated list
ABC PATH=/a/b/c PORT= 80
Example, the following expression returns a
Returns the value of the Domain field
First cookie with the specified name. For
DOMAIN=.xyz.com
Named cookie as a , separated list. For
From the cookie Set-Cookie Customer
Returns the value of Version field of the nth
Operations for Http Headers
Operations That Evaluate Http Headers
Header type exists
Following returns a Boolean True
Any instance of the header value
Following is an example of request with two headers
Does not concatenate the different values
Following is an example of a request
STR string
Instance to the first
Following extracts the string def from the last
Used in bidirectional policies
Or a response. This operation returns the header that
Occurs instance number of places before the final
Instance number argument cannot exceed
Prefixes That Extract Cache-Control Headers
Prefixes for Cache-Control Headers
Operations for Cache-Control Headers
Cannot exceed
Http Header Operation Description
Operations That Evaluate Cache-Control Headers
127
Has the value Must-Revalidate
Has the value Min-Fresh
Has the value Max-Stale
Has the value No-Transform
Expressions for Extracting Segments of URLs
Prefixes That Evaluate Http Request or Response Length
Expressions for Numeric Http Payload Data Other Than Dates
Prefixes That Extract URLs
URL Prefix Description
Html or XML Operation Description
Operations That Evaluate Html and XML Encoding
Returns the response status code
Converts unsafe URL characters to %xx values
Where xx is a hex-based representation
Specifies how to treat the plus character +.
Read-only operation
Decoded to http//, where the colon is
With the character Y where XXX represents
Where the colon is the Ascii equivalent
Where WW and XX represent two distinct
GET Operation Description
Expressions for TCP, UDP, and Vlan Data
Prefixes that Extract TCP and UDP Data
Domain and the priority for each server
Enables locating the domain name that is
MX mail exchanger. This DNS record describes
NS. This is a name server record that includes a
XPath and Json Expressions
XPath and Json Expression Prefixes that Return Text
File Book creator person Namename , titletitle
Or a string. Node-sets are converted to
XPath string conversion routine
Json file and returns a Boolean True if
First 1000 bytes of the body of the Json
For example, consider the following Json
That are enclosed by /Book a node-set
File and returns the corresponding string
MARKUPxp%/Book/creator%
Text.XPATHWITH
Bytes of the body
Citrix NetScaler Policy Configuration and Reference Guide
Advanced Expressions Parsing SSL Certificates
About SSL and Certificate Expressions
SSL transaction
Prefixes for Text-Based SSL and Certificate Data
Returns the SSL client certificate in the current
SSL cryptographic cipher is exportable
Advanced Expressions Parsing SSL Certificates
Prefixes for Numeric Data in SSL Certificates
Expressions for SSL Certificates
Returns a Boolean True if the client has an SSL
Issuer in the certificate as a name-value list. An
Based on the preceding Issuer definition
Returns the Distinguished Name DN
Certificate as a name-value list. An equals sign
Returns the Issuer Distinguished Name
An Authority Key Identifier extension
= is the delimiter for the name and the value
False
CLIENT.SSL.CLIENTCERT.ISSUER
IGNOREEMPTYELEMENTS.COUNT
Citrix NetScaler Policy Configuration and Reference Guide
Expressions for IP Addresses and IP Subnets
Prefixes That Evaluate IP and MAC Addresses
Prefixes for IPV4 Addresses and IP Subnets
Operations for IPV4 Addresses
Operations on IPV4 Addresses
About IPv6 Expressions
Qual1.qual2.qual3.qual4.qual5.qual6
IP header
Expression Prefixes for IPv6 Addresses
IPv6 Expression Prefixes that Return Text
Returns the IPv6 address in the source field of the IP
IPv6 Operation Description
Operations for IPV6 Prefixes
Operations That Evaluate IPv6 Addresses
Operations for MAC Addresses
Expressions for MAC Addresses
Prefixes for MAC Addresses
Prefixes That Evaluate MAC Addresses
155
Expressions for Numeric Client and Server Data
Prefixes That Evaluate Numeric Client and Server Data
Citrix NetScaler Policy Configuration and Reference Guide
Matching Text With Strings in a Set
Patternsetname
Operators That Use a Pattern Set
Matching Operators Description
To patternsetname
Name
Setname
Configuring a Pattern Set
161
At a NetScaler command prompt, type
163
Add policy patset myPatSet
Matching Text With a Pattern
165
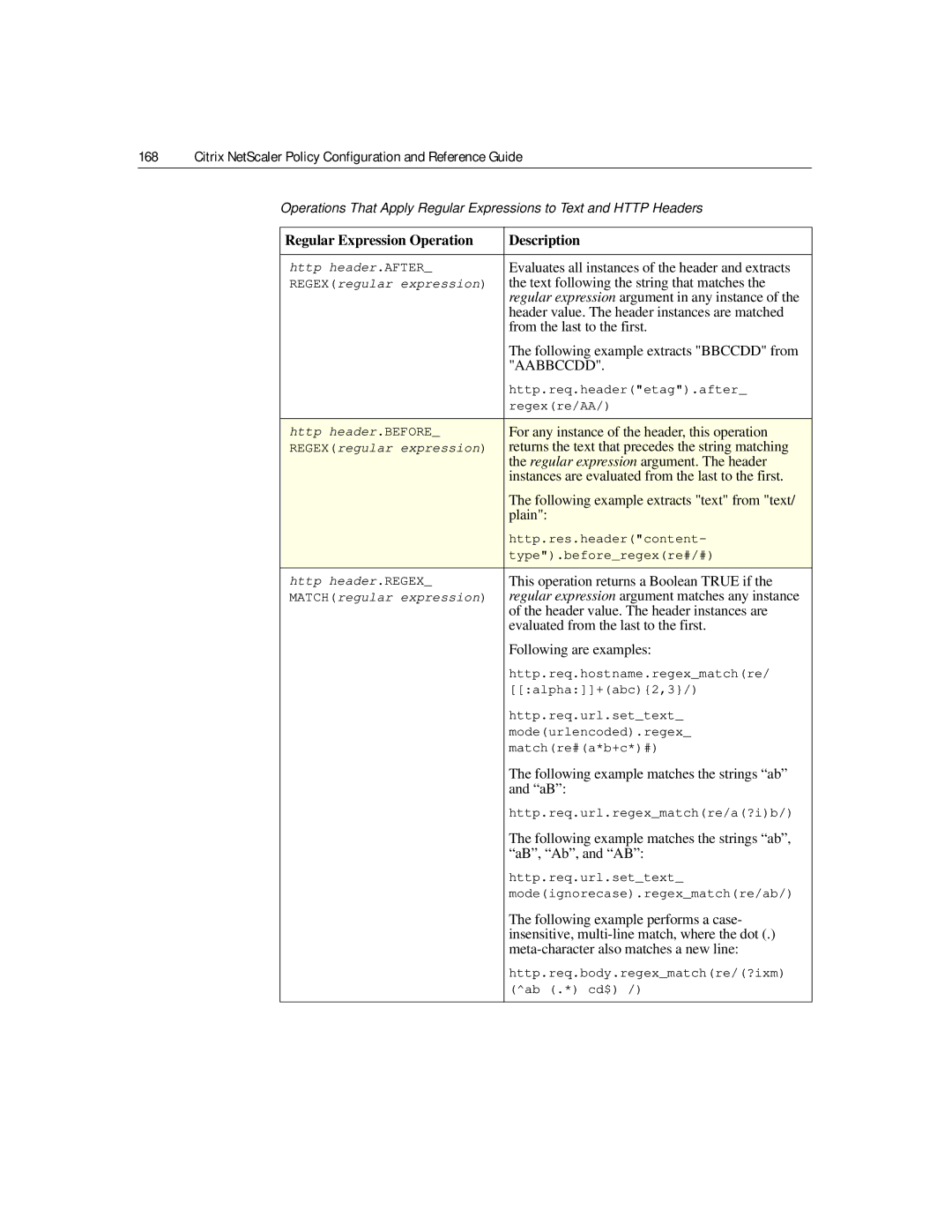
Basic Characteristics of Regular Expressions
Operations for Regular Expressions
From text/plain
Selects text that precedes the string that matches
Regular expression argument. If the regular
Expression does not match any text in the target
Regular Expression Operation Description
Settextmodeignorecase
Header value. The header instances are matched
Insensitive, multi-line match, where the dot
Text following the string that matches
From the last to the first
Following example selects NS-CACHE-9.0
Transforming Text and Numbers into Different Data Types
First
Typecasting Operations
As the delimiter, an uppercase P is not treated as a
If the current text mode is Ignorecase and you specify
Are ignored
Delimiter
Treats a numeric string like an IP address
Hostname path? query, and the text mode is set to
Urlencoded by default
For example, the following policy matches Http requests
For example, this policy would extract 4444 from
Following policy extracts a numeric portion of a query
String, adds 4 to the number, and inserts an Http header
Following Http response header
HTTP.REQ.COOKIE.TYPECASTHTTPHEADERT
HTTP.REQ.SETCOOKIE
HTTP.REQ.COOKIE.TYPECASTHTTPHEADER
For example, the following expression converts
Converts the designated text to a multi-line Http header
That you specify in a name argument
MyHeader to InHeader
Betweengmt 2004, GMT 2006 True
Eqgmt 2005 Dec False
Time value argument t
Eqgmt 2005 True
EQLocal 2005 May True or FALSE, depending on
GTLocal 2005 May True or FALSE, depending on
Gtgmt 2004 True
Gtgmt 2005 Jan True
Gtgmt 8h True
LELocal 2005 May True or FALSE, depending on
Legmt 2006 True
Legmt 2005 Dec True
Legmt 8h False
Value as an integer that ranges from 0 to
Most recent reboot or the number of seconds to the next
Time is in the future scheduled reboot time, the integer is
Value as an integer that ranges from 1 January to
Time1 and time2
Double to an integer
Extracts the year from the current system time and returns
Transforms the double-precision number represented by
Expressions for Controlling the Traffic Rate
Advanced Policies Controlling Rate of Traffic
About Policies that Monitor the Traffic Rate
Configuring Policies That Control the Traffic Rate
Chapter
About Calling Out to an External Application
About Http Callout Policies
Following is an example of a response
187
Parameter Specifies
Configuring an Http Callout Policy
Elements in an Http Callout Policy
Expression that derives the value. Examples
Attribute-based Http Method httpMethod
Server mutually
URL stem expression urlStemExpr
NetScaler does not check the validity of this request. You
Example, if you configure a return type of text, the result
Expression to 8191 characters
Must manually validate the request
191
To modify a callout policy using the NetScaler command line
Examples
Invoking an Http Callout Policy
To delete a callout policy using the NetScaler command line
To view a callout policy using the NetScaler command line
193
If the return type is NUM, the following expression is valid
195
Citrix NetScaler Policy Configuration and Reference Guide
Configuring Classic Policies Expressions
Where Classic Policies Are Used
Http
Configuring Classic Policies and Expressions
Auditing of user access
Viewing Classic Policies
Click Policies
Configuring a Classic Policy
201
At the command line, type
To create a classic policy using the NetScaler command line
Configuring a Classic Expression
203
REQ.IP.SOURCEIP == 200.0.0.0 -netmask
205
Flow Type.protocol.qualifier.operator.value.header Name
Binding a Classic Policy
207
Configure Virtual Server dialog box, click the Policies tab
Creating Named Classic Expressions
209
Citrix NetScaler Policy Configuration and Reference Guide
Expression Prefix Descriptions
Expressions Reference
Advanced Expressions
Citrix NetScaler Policy Configuration and Reference Guide
Appendix a Expressions Reference
Operates on the Vlan through which the current
Expression Prefixes for Text in Http
Ignores spaces in the data. See the table Http
Appendix a Expressions Reference 217
Obtains the Expires field of the cookie as a date
Appendix a Expressions Reference 219
SERVER.INTERFACE.ID.EQLA/1
Appendix a Expressions Reference 221
VPNs, on
Ignores spaces in the data. For an example, see
Appendix a Expressions Reference 223
Expression Element Definition
Classic Expressions
Operators
General Expressions
Appendix a Expressions Reference 225
REQ.SSL
REQ.SSL.CLIENT.CERT.ISSUER
REQ.HTTP.URLQUERYLEN
REQ.SSL.CLIENT.CERT
Appendix a Expressions Reference 227
Actual Expression Definition
Client Security Expressions
Expression Element
Expression Definition
Network-Based Expressions
Appendix a Expressions Reference 229
Time
Date/Time Expressions
File System Expressions
Date
Appendix a Expressions Reference 231
Built-In Named Expressions General
Appendix a Expressions Reference 233
Always returns a value of False
Nstrue Nsurlpathbin
Nsfarclient
Nsmsexcel Nsmsie Nsmsppt Nsmsword
Appendix a Expressions Reference 235
Built-InNamed Expressions Anti-Virus
Built-InNamed Expressions Personal Firewall
Any version of Norton Internet Security
Built-InNamed Expressions Client Security
Expression Definition Norton Internet Security
Expression Type Sample Expressions
Summary Examples of Advanced Expressions and Policies
Examples of Advanced Expressions
Http request based on the file
Content-Type header
Look for a particular file type in an
Extension
Examples of Advanced Expressions and Policies
Purpose Example
Responder functionality
To https// in all URLs
This policy uses
Modify a URL to redirect
Through unchanged
Limit the number
Check the client IP
NS-Client header
Remove old headers from
Request and insert an
Then modify the insert
Request, insert an
NS-Client header,
Header action so that
Citrix NetScaler Policy Configuration and Reference Guide
Tutorial Examples of Advanced Policies for Rewrite
Redirecting an External URL to an Internal URL
Bind the policy globally
Appendix C
Redirecting a Query
Redirecting Http to Https
247
Removing Unwanted Headers
249
Reducing Web Server Redirects
Masking the Server Header
Add rewrite policy polmask-server true actmask-server
Tutorial Examples of Classic Policies
Citrix NetScaler Policy Configuration and Reference Guide
Appendix D Tutorial Examples of Classic Policies 253
REQ.HTTP.HEADER URL Contains string
Application Firewall Policy to Protect Scripted Web Pages
Appendix D Tutorial Examples of Classic Policies 255
DNS Policy to Drop Packets from Specific IPs
SSL Policy to Require Valid Client Certificates
Add dns policy polddosdrop
Citrix NetScaler Policy Configuration and Reference Guide
Migration of Apache modrewrite Rules to Advanced Policies
Converting URL Variations into Canonical URLs
Apache modrewrite solution for converting a URL
NetScaler solution for converting a URL
Converting Host Name Variations to Canonical Host Names
Moving a Document Root
Apache modrewrite solution for moving the document root
NetScaler solution for moving the document root
Appendix E
Moving Home Directories to a New Web Server
Working with Structured Home Directories
NetScaler solution for redirection if a URL is wrong method
Apache modrewrite solution for structured home directories
NetScaler solution for structured home directories
Redirecting Invalid URLs to Other Web Servers
NetScaler solution for rewriting a URL based on the time
Rewriting a URL Based on Time
265
Redirecting to a New File Name Invisible to the User
Redirecting to New File Name User-Visible URL
Accommodating Browser Dependent Content
Apache modrewrite solution for browser-specific settings
Blocking Access by Robots
267
Creating Extensionless Links
Blocking Access to Inline Images
NetScaler solution for blocking access to an inline image
269
NetScaler policy for adding a .php extension to all requests
Apache modrewrite solution
Redirecting a Working URI to a New Format
NetScaler solution using pattern sets
NetScaler solution
NetScaler solution using regular expressions
Ensuring That a Secure Server Is Used for Selected Pages
Bind patset pat1 page4 Bind patset pat1 page5
New Operators for Extracting and Evaluating Numeric Data
New Advanced Expression Operators in This Release
Operators for Extracting and Evaluating Numeric Data
Number.TYPECASTIPADDRESSAT
Operators Operation
Operators for Extracting and Evaluating Text
New Operators for Evaluating Text
New Operators for Extracting and Evaluating Http data
Operators for Extracting and Evaluating Http Data
Operators for the Client and ipv6 Expression Prefixes
Operators for Client and ipv6 Expression Prefixes
XPath and Json Operators for Evaluating XML and Json Text
XPath and Json Operators for Evaluating XML and Json Data
Operators for Evaluating Groups to Which a User Belongs
Operators for Evaluating Groups to Which a User Belongs
Index
Introduction to 224 migration to advanced
Index 279
RES.VLANID
CLIENT.ETHER.DSTMAC
Index
HTTP.RES.SETCOOKIE2.COOKIEname, i
Omain 82 VPN.CLIENTLESSHOSTURL.HOSTNAME.E
Authkeyid
Citrix NetScaler Policy Configuration and Reference Guide
Index
Useinvocationresult
VPN 65 Character 57 ? character
Citrix NetScaler Policy Configuration and Reference Guide