AMD AthlonTM Processor
Trademarks
Contents
Instruction Decoding Optimizations
Cache and Memory Optimizations
Scheduling Optimizations
Floating-Point Optimizations
General x86 Optimization Guidelines 127
Appendix B Pipeline and Execution Unit Resources Overview
Appendix E Programming the Mtrr and PAT
List of Figures
Xii
List of Tables
Xiv
Revision History
Xvi
About this Document
Introduction
Source Level Optimizations. Describes optimizations that
AMD Athlon Processor Family
AMD Athlon Processor Microarchitecture Summary
AMD Athlon Processor Microarchitecture Summary
AMD Athlon Processor x86 Code Optimization
Top Optimizations
Optimization Star
Memory Size and Alignment Issues
Group I Optimizations Essential Optimizations
Use the 3DNow! Prefetch and Prefetchw Instructions
Select DirectPath Over VectorPath Instructions
Group II Optimizations-Secondary Optimizations
Load-Execute Instruction Usage
Use Load-Execute Instructions
Use 3DNow! Instructions
Take Advantage of Write Combining
Avoid Branches Dependent on Random Data
Avoid Placing Code and Data in the Same 64-Byte Cache Line
22007E/0 November
Use 32-Bit Data Types for Integer Code
Source Level Optimizations
Example 1 Avoid
Consider the Sign of Integer Operands
Example Preferred
Example Avoid
Use Array Style Instead of Pointer Style Code
Use unsigned types for
Use signed types for
Vertex
Example 2 Preferred
Avoid Unnecessary Store-to-Load Dependencies
Completely Unroll Small Loops
Avoid Unnecessary Store-to-Load Dependencies
Consider Expression Order in Compound Branch Conditions
Optimize Switch Statements
Switch Statement Usage
Use Prototypes for All Functions
Generic Loop Hoisting
Use Const Type Qualifier
Example
Generalization for Multiple Constant Control Code
Declare Local Functions as Static
Introduce Explicit Parallelism into Code
Dynamic Memory Allocation Consideration
Explicitly Extract Common Subexpressions
Example
Language Structure Component Considerations
Avoid
Preferred
Original ordering Avoid
Sort Local Variables According to Base Type Size
New ordering, with padding Preferred
Improved ordering Preferred
Accelerating Floating-Point Divides and Square Roots
Accelerating Floating-Point Divides and Square Roots
Avoid Unnecessary Integer Division
AMD Athlon Processor x86 Code Optimization
Overview
Instruction Decoding Optimizations
Load-Execute Instruction Usage
Select DirectPath Over VectorPath Instructions
Use Load-Execute Integer Instructions
TOP
Use Short Instruction Lengths
Align Branch Targets in Program Hot Spots
Example 2 Avoid
Avoid Partial Register Reads and Writes
Replace Certain Shld Instructions with Alternative Code
Use 8-Bit Sign-Extended Immediates
Code Padding Using Neutral Code Fillers
Use 8-Bit Sign-Extended Displacements
Recommendations for the AMD Athlon Processor
Code Padding Using Neutral Code Fillers
AMD Athlon Processor x86 Code Optimization
NOP6EDI
AMD Athlon Processor x86 Code Optimization
Cache and Memory Optimizations
Memory Size and Alignment Issues
Avoid Memory Size Mismatches
Use the 3DNow! Prefetch and Prefetchw Instructions
Align Data Where Possible
Code
Example Multiple Prefetches
MOV ECX, -LARGENUM
Prefetch Distance = 200 DS/C bytes
Determining Prefetch Distance
Avoid Placing Code and Data in the Same 64-Byte Cache Line
Take Advantage of Write Combining
Store-to-Load Forwarding Pitfalls -True Dependencies
Store-to-Load Forwarding Restrictions
Example 4 Avoid
Example 3 Avoid
Example 6 Avoid
Example 5 Preferred
Example 7 Avoid
Summary of Store-to-Load Forwarding Pitfalls to Avoid
Stack Alignment Considerations
Align Tbyte Variables on Quadword Aligned Addresses
Sort Variables According to Base Type Size
Avoid Branches Dependent on Random Data
Branch Optimizations
Blended AMD-K6and AMD Athlon Processor Code
AMD Athlon Processor Specific Code
Example 6 Increment Ring Buffer Offset
Always Pair Call and Return
Example 7 Integer Signum Function
Muxing Constructs
Replace Branches with Computation in 3DNow! Code
Code
Sample Code Translated into 3DNow! Code
3DNow! code
MM5
Pfsub
Psrad
Avoid Far Control Transfer Instructions
Avoid the Loop Instruction
Avoid Recursive Functions
Schedule Instructions According to their Latency
Scheduling Optimizations
Unrolling Loops
Complete Loop Unrolling
Partial Loop Unrolling
With Partial Loop Unrolling
Without Loop Unrolling
Control For Partially
Deriving Loop
Unrolled Loops
Example 1 rolled loop
Overview
Use Function Inlining
Always Inline Functions if Called from One Site
Avoid Address Generation Interlocks
Minimize Pointer Arithmetic in Loops
Use Movzx and Movsx
MOV ECX, Maxsize
Example 3 Preferred
Push Memory Data Carefully
Push Memory Data Carefully
Replace Divides with Multiplies
Integer Optimizations
Multiplication by Reciprocal Division Utility
Unsigned Division by Multiplication of Constant
Simpler Code for
Signed Division by Multiplication of Constant
Restricted Dividend
Signed Division By 2n
Signed Division By
Remainder of Signed
Integer 2 or
Integer 2n or -2n
Use Alternative Code When Multiplying by a Constant
ADD REG1, REG1 REG1, REG2 SHL
Use MMX Instructions for Integer-Only Work
Latency of Repeated String Instructions
Repeated String Instruction Usage
Guidelines for Repeated String Instructions
Ensure DF=0 UP
Using Movq
Align Source
Destination with
Efficient 64-Bit Integer Arithmetic
Use XOR Instruction to Clear Integer Registers
Example 5 Right shift
Example 4 Left shift
Example 6 Multiplication
EBX, ESP+12 Dividendlo
Example 7 Division
Example 8 Remainder
SHR EDX
Step
Efficient Implementation of Population Count Function
Bit field. Thus the following computation is performed
MOV EDX, EDX SHR
Derivation of Multiplier Used for Integer Division by
Utility sdiv.exe was compiled using the following code
MOV ECX EDX Imul ADD SHR SAR
Ensure All FPU Data is Aligned
Floating-Point Optimizations
Use Multiplies Rather than Divides
Use Ffreep Macro to Pop One Register from the FPU Stack
Floating-Point Compare Instructions
Use the Fxch Instruction Rather than FST/FLD Pairs
Avoid Using Extended-Precision Data
Example 1 Fast
Minimize Floating-Point-to-Integer Conversions
Example 2 Potentially faster
Example 4 Fastest
Example 3 Potentially faster
Floating-Point Subexpression Elimination
104
Take Advantage of the Fsincos Instruction
106
Use 3DNow! Instructions
3DNow! and MMX Optimizations
Use Femms Instruction
Optimized 14-Bit Precision Divide
Use 3DNow! Instructions for Fast Division
Optimized Full 24-Bit Precision Divide
Newton-Raphson Reciprocal
Pipelined Pair of 24-Bit Precision Divides
Optimized 24-Bit Precision Square Root
Optimized 15-Bit Precision Square Root
Newton-Raphson Reciprocal Square Root
AMD Athlon
3DNow! and MMX Intra-Operand Swapping
Specific Code
Blended Code
Use MMX Pxor to Negate 3DNow! Data
Fast Conversion of Signed Words to Floating-Point
Both Numbers
Use MMX Pcmp Instead of 3DNow! Pfcmp
Positive One Negative, One
Positive
AMD-K6and AMD Athlon Processor Blended Code
Use MMX Instructions for Block Copies and Block Fills
116
Processor Specific
Use MMX Pxor to Clear All Bits in an MMX Register
Use MMX Pcmpeqd to Set All Bits in an MMX Register
Optimized Matrix Multiplication
MOV EBX, RES
Optimized Matrix Multiplication 121
Data
Use 3DNow! Pavgusb for MPEG-2 Motion Compensation
MM0=QWORD1
Stream of Packed Unsigned Bytes
Complex Number Arithmetic
Short Forms
General x86 Optimization Guidelines
Register Operands
Dependencies
Stack Allocation
Introduction
AMD Athlon Processor Microarchitecture
Superscalar Processor
AMD Athlon Processor Microarchitecture
AMD Athlon Processor Microarchitecture 131
Branch Prediction
Predecode
Early Decoding
Data Cache
Instruction Control Unit
Integer Execution Unit
Integer Scheduler
Floating-Point Scheduler
12 to
Floating-Point Execution Unit
Load/Store Unit
Load-Store Unit LSU
Write Combining
L2 Cache Controller
AMD Athlon System Bus
140 AMD Athlon Processor Microarchitecture
Fetch and Decode Pipeline Stages
Pipeline and Execution Unit Resources Overview
C T L R O M
Cycle 2-SCAN
Cycle 1-FETCH
Cycle 3 DirectPath
Cycle 3 VectorPath
Integer Pipeline Stages
Integer Pipeline Stages
Cycle 8-EXEC
Cycle 7-SCHED
Cycle 9-ADDGEN
Cycle 10 -DCACC
Floating-Point Pipeline Stages
Floating-Point Pipeline Stages
Cycle 8-REGREN
Cycle 7-STKREN
Cycle 9-SCHEDW
Cycle 10 -SCHED
Terminology
Execution Unit Resources
Operands
Results
Integer Pipeline Operation Types
Integer Pipeline Operations
Integer Decode Types
Floating-Point Pipeline Operation Types
Floating-Point Pipeline Operations
Floating-Point Decode Types
Load/Store Unit Stages
Load/Store Pipeline Operations
Stage 1 Cycle Stage 2 Cycle Stage 3 Cycle
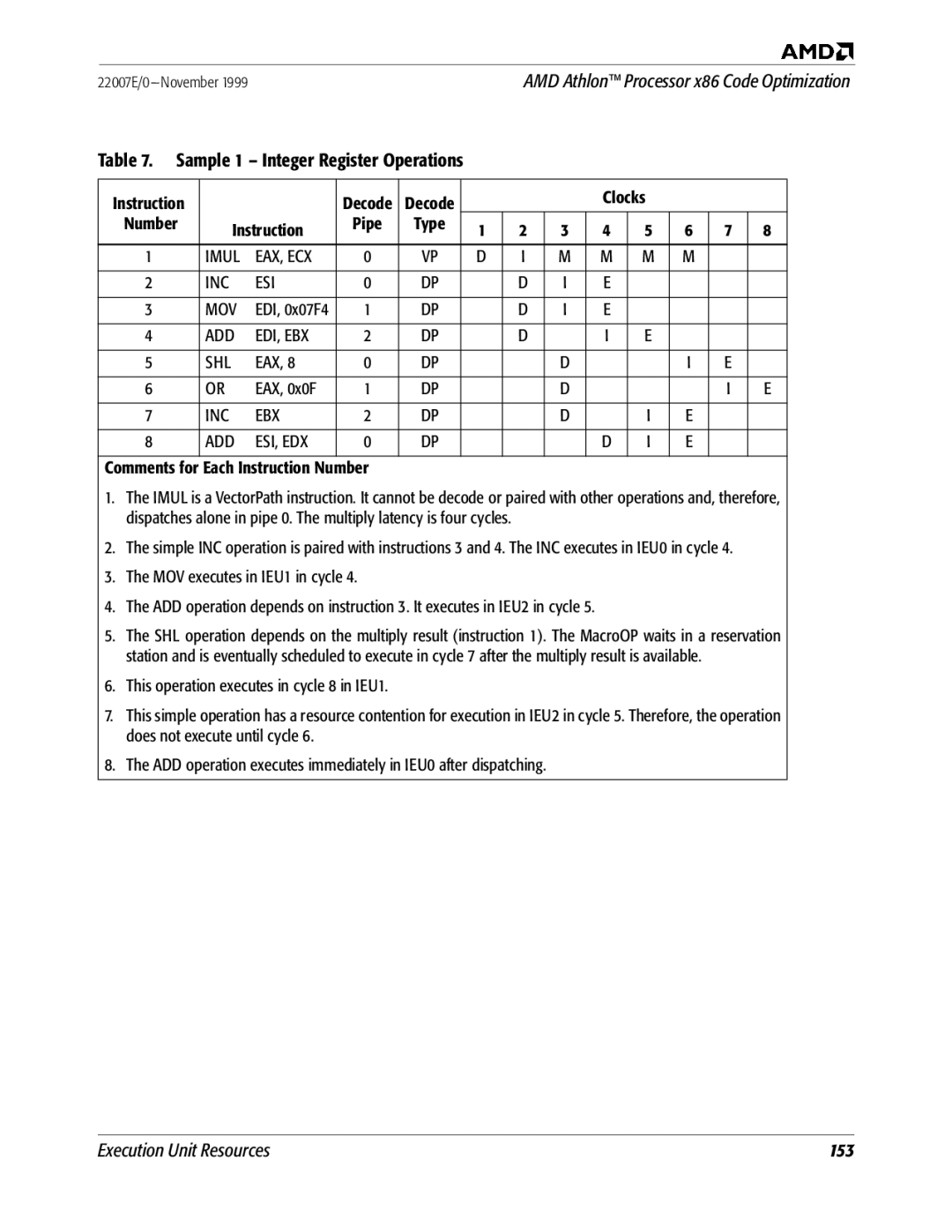
Code Sample Analysis
ADD EDI, EBX SHL
Imul EAX, ECX INC ESI MOV
INC EBX ADD ESI, EDX
DEC EDX MOV EDI, ECX SUB
Sample 2 Integer Register and Memory Load Operations
SAR
Implementation Write Combining
Appendix C
Write-Combining Definitions and Abbreviations
What is Write Combining?
Programming Details
Write-Combining Operations
INIT, Halt
Write Combining Completion Events
Sending Write-Buffer Data to the System
AMD Athlon System Bus Commands Generation Rules
160 Write-Combining Operations
Performance Counter Usage
Performance-Monitoring Counters
PerfEvtSel30 Registers
PerfEvtSel30 MSRs MSR Addresses C0010000h-C0010003h
Performance Counter Usage 163
Performance-Monitoring Counters
73h
65h
Snoop hits
74h
Waited to use the L2
Event Source Event Description
Instruction cache fetches
Instruction cache misses
PerfCtr30 MSRs MSR Addresses C0010004h-C0010007h
Starting and Stopping the Performance-Monitoring Counters
Event and Time-Stamp Monitoring Software
Monitoring Counter Overflow
170 Monitoring Counter Overflow
Memory Type Range Register Mtrr Mechanism
Programming the Mtrr
172 Memory Type Range Register Mtrr Mechanism
FFFFFFFFh
Fixed Ranges
100000h Kbytes each Fixed Ranges C0000h 80000h
Memory Type Encodings
Memory Types
Mtrr Capability
Register Format
Memory Type Range Register Mtrr Mechanism 175
Standard Mtrr Types and Properties
Attribute Table MSR 277h
Attribute Table PAT
PATi 3-Bit Encodings
PAT Entry Reset Value
MTRRs and PAT
PATi
PAT Memory Type Mtrr Memory Type
Effective Memory Type Based on PAT and MTRRs
Input Memory Type
Final Output Memory Types
Attribute Table PAT 181
9FFFF 9BFFF 97FFF 93FFF 8FFFF 8BFFF 87FFF 83FFF
7FFFF 6FFFF 5FFFF 4FFFF 3FFFF 2FFFF 1FFFF 0FFFF
Bffff Bbfff B7FFF B3FFF Affff Abfff A7FFF A3FFF
C7FFF C6FFF C5FFF C4FFF C3FFF C2FFF C1FFF C0FFF
Attribute Table PAT 183
MTRRphysMaskn Register Format
MTRR-Related Model-Specific Register MSR Map
186
Instruction Dispatch Execution Resources
Appendix F
AAA
Integer Instructions
AAD
AAM
ADC mreg8, reg8
ModR/M Decode Byte
ADC mem8, reg8
ADC mreg16/32, reg16/32
Bswap EAX
Bound
Bswap ECX
Bswap EDX
CLC
CBW/CWDE
CLD
CLI
CMOVE/CMOVZ reg16/32, mem16/32 0Fh
CMOVE/CMOVZ reg16/32, reg16/32 0Fh
CMOVG/CMOVNLE reg16/32, reg16/32 0Fh
CMOVG/CMOVNLE reg16/32, mem16/32 0Fh
CWD/CDQ
Cpuid
DAA
DAS
AL, DX
Enter
AX, DX
EAX, DX
Invlpg
Invd
Leave
Lahf
LOOPNE/LOOPNZ disp8 E0h
LOOPE/LOOPZ disp8 E1h
LSL reg16/32, mreg16/32 0Fh 03h
LSL reg16/32, mem16/32 0Fh 03h
NOP Xchg EAX, EAX
OUT DX, AX
OUT DX, AL
OUT DX, EAX
POP ES
POP ESP
POP EBX
POP EBP
POP ESI
Rdpmc
Rdmsr
Rdtsc
Sahf
SBB mem16/32, reg16/32
SBB mreg16/32, reg16/32
SBB reg8, mreg8
SBB reg8, mem8
Sets mem8
Sets mreg8
Setns mreg8
Setns mem8
STD
STC
STI
Sysenter
Syscall
Sysexit
Sysret
Xchg EAX, ECX
Xchg EAX, EAX
Xchg EAX, EDX
Xchg EAX, EBX
Emms
MMX Instructions
DFh
Pandn mmreg1, mmreg2
Pandn mmreg, mem64
Pcmpeqb mmreg1, mmreg2
FADD/FMUL
FPU
MMX Extensions
Floating-Point Instructions
Fcos
Fcompp
Fdecstp
Finit
Fincstp
FLD1
FLDL2T
FLDL2E
FLDLG2
FLDLN2
Ftst
Fstsw AX
Fucom
Fucomp
Femms
DNow! Instructions
DNow! Extensions
DirectPath Instructions
DirectPath versus VectorPath Instructions
BT mreg16/32, reg16/32 BT mreg16/32, imm8 BT mem16/32, imm8
DirectPath Integer Instructions
CBW/CWDE CLC CMC
INC mreg8 INC mem8 INC mreg16/32 INC mem16/32 JO short disp8
DEC mreg8 DEC mem8 DEC mreg16/32 DEC mem16/32
222 DirectPath Instructions
DirectPath Instructions 223
224 DirectPath Instructions
Wait Xchg EAX, EAX
226 DirectPath Instructions
DirectPath MMX Instructions
DirectPath MMX Extensions
Fcompp Fdecstp
DirectPath Floating-Point Instructions
Fist mem16int
FLD1 FLDL2E FLDL2T FLDLG2 FLDLN2 Fldpi Fldz
Ftst Fucom Fucomp Fucompp Fwait Fxch
VectorPath Integer Instructions
VectorPath Instructions
AAA AAD AAM AAS
CLD CLI Clts
AL, DX AX, DX EAX, DX Invd Invlpg
Instruction Mnemonic DIV EAX, mem16/32
Push mreg16/32 Push mem16/32
POP mreg 16/32 POP mem 16/32
PUSHA/PUSHAD PUSHF/PUSHFD
Rdmsr Rdpmc Rdtsc
VectorPath MMX Extensions
VectorPath MMX Instructions
Syscall Sysenter Sysexit Sysret
Wbinvd Wrmsr
Fptan Fpatan Frndint
VectorPath Floating-Point Instructions
Fscale Fsin Fsincos
Fxam Fxtract FYL2X FYL2XP1
236
Index
238 Index
Index 239
240 Index