Software Optimization Guide For AMD64 Processors
2001 2005 Advanced Micro Devices, Inc. All rights reserved
Contents
General 64-Bit Optimizations
Chapter Cache and Memory Optimizations
Chapter Integer Optimizations 159
Chapter X87 Floating-Point Optimizations 237
Appendix B Implementation of Write-Combining
Viii
Index
Software Optimization Guide for AMD64 Processors
Tables
Tables
Xii Tables
Figures
Xiv
Revision History
Xvi Revision History
Intended Audience
Getting Started Quickly
Using This Guide
Typographic Notation
Special Information
Numbering Systems
Providing Feedback
Internal Instruction Formats
Important New Terms
Primitive Operations
Mrom
Types of Instructions
Instructions, Macro-ops and Micro-ops
Key Optimizations by Rank
Key Optimizations
Guideline
Optimizations by Rank
C++ Source-Level Optimizations
C++ Source-Level Optimizations
Application
Declarations of Floating-Point Values
Optimization
Rationale
Using Arrays and Pointers
Example
Matrix
Additional Considerations
Instead, use the equivalent array notation
Unrolling Small Loops
Related Information
Expression Order in Compound Branch Conditions
Chapter C++ Source-Level Optimizations
Long Logical Expressions in If Statements
Arrange Boolean Operands for Quick Expression Evaluation
If *p == y && strlenp
Dynamic Memory Allocation Consideration
Unnecessary Store-to-Load Dependencies
Listing 3. Avoid
Application
Matching Store and Load Size
Examples
Listing 6. Preferred
C++ Source-Level Optimizations
Switch and Noncontiguous Case Expressions
Example
Related Information
Arranging Cases by Probability of Occurrence
Use of Function Prototypes
Use of const Type Qualifier
Generic Loop Hoisting
Rationale and Examples
Listing
Chapter C++ Source-Level Optimizations
Local Static Functions
Explicit Parallelism in Code
Listing 11. Preferred
Extracting Common Subexpressions
Listing 15. Example 2 Preferred
Sorting and Padding C and C++ Structures
Sorting and Padding C and C++ Structures
C++ Source-Level Optimizations
Sorting Local Variables
Related Information
Replacing Integer Division with Multiplication
Frequently Dereferenced Pointer Arguments
Listing 16. Avoid
Listing 17. Preferred
Array Indices
23 32-Bit Integral Data Types
Rational
Sign of Integer Operands
Listing 20. Example 2 Avoid
Accelerating Floating-Point Division and Square Root
Examples
Fast Floating-Point-to-Integer Conversion
Listing 23. Slow
Speeding Up Branches Based on Comparisons Between Floats
Branches Dependent on Integer Comparisons Are Fast
Comparisons against Positive Constant
Comparisons among Two Floats
Improving Performance in Linux Libraries
Software Optimization Guide for AMD64 Processors
General 64-Bit Optimizations
This code performs 64-bit addition using 32-bit registers
64-Bit Registers and Integer Arithmetic
ESP+8ESP+4 = multiplicand
64-Bit Arithmetic and Large-Integer Multiplication
Background
G1 = c3 E1 + f1 + g0 = c2 D1 + e0 + f0 = c1 D0 = c0
XMM
END
Text Segment
128-Bit Media Instructions and Floating-Point Operations
32-Bit Legacy GPRs and Small Unsigned Integers
Chapter General 64-Bit Optimizations
General 64-Bit Optimizations
Instruction-Decoding Optimizations
DirectPath Instructions
Load-Execute Instructions
Load-Execute Integer Instructions Optimization
Movss xmm0, floatvar1 mulss xmm0, floatvar2
Application
Branch Targets in Program Hot Spots
32/64-Bit vs -Bit Forms of the LEA Instruction
Take Advantage of x86 and AMD64 Complex Addressing Modes
Cmpb %al,0x68e35%r10,%r13
Short Instruction Encodings
Partial-Register Reads and Writes
Avoid
Functions That Do not Allocate Local Variables
Using Leave for Function Epilogues
Functions That Allocate Local Variables
Traditional function epilogue looks like this
Alternatives to Shld Instruction
Lea reg1, reg1*8+reg2
10 8-Bit Sign-Extended Immediate Values
11 8-Bit Sign-Extended Displacements
Code Padding with Operand-Size Override
NOP
Instruction-Decoding Optimizations
Cache and Memory Optimizations
Bit Avoid
Memory-Size Mismatches
Examples-Store-to-Load-Forwarding Stalls
Avoid
Preferred If Stores Are Close to the Load
Preferred If the Contents of MM0 are No Longer Needed
Examples-Large-to-small Mismatches
Preferred If the Stores and Loads are Close Together, Option
Natural Alignment of Data Objects
Cache-Coherent Nonuniform Memory Access ccNUMA
CPU0
Dual-Core AMD Opteron Processor Configuration
OS Implications
Multiprocessor Considerations
Narrow-to-Wide Store-Buffer Data-Forwarding Restriction
Store-to-Load Forwarding Restrictions
Store-to-Load Forwarding Pitfalls-True Dependencies
100
101
Wide-to-Narrow Store-Buffer Data-Forwarding Restriction
Misaligned Store-Buffer Data-Forwarding Restriction
Store-to-Load Forwarding-False Dependencies
High-Byte Store-Buffer Data-Forwarding Restriction
One Supported Store-to-Load Forwarding Case
102
Summary of Store-to-Load-Forwarding Pitfalls to Avoid
103
104
Prefetch Instructions
Prefetching versus Preloading
PREFETCH/W versus PREFETCHNTA/T0/T1/T2
Unit-Stride Access
Hardware Prefetching
105
106
Prefetchw versus Prefetch
Write-Combining Usage
Multiple Prefetches
107
Determining Prefetch Distance
108
Memory-Limited Code
Processor-Limited Code
Definitions
Cache and Memory Optimizations
Prefetch at Least 64 Bytes Away from Surrounding Stores
111
Streaming-Store/Non-Temporal Instructions
Write-combining
113
Fields Used to Address the Multibank L1 Data Cache
How to Know If a Bank Conflict Exists
L1 Data Cache Bank Conflicts
115
Placing Code and Data in the Same 64-Byte Cache Line
Sorting and Padding C and C++ Structures
117
118
119
120
Memory Copy
Copying Small Data Structures
121
Optimized Stack Usage
Stack Considerations
Extend Arguments to 32 Bits Before Pushing onto Stack
122
Cache Issues when Writing Instruction Bytes to Memory
123
Interleave Loads and Stores
124
This Chapter
125
Density of Branches
126
127
Align
Two-Byte Near-Return RET Instruction
128
129
Unsigned Integer min Function z = x y ? x y
Branches That Depend on Random Data
Signed Integer ABS Function x = labsx
130
Conditional Write
131
Pairing Call and Return
132
Recursive Functions
133
134
Nonzero Code-Segment Base Values
135
136
Replacing Branches with Computation
Muxing Constructs
137
SSE Solution Preferred
MMX Solution Avoid
Example 1 3DNow! Code
Sample Code Translated into AMD64 Code
Example 1 C Code
Example 2 C Code
Example 4 C Code
Example 3 C Code
Example 3 3DNow! Code
Example 4 3DNow! Code
140
Example 5 C Code
Example 5 3DNow! Code
Loop Instruction
141
Far Control-Transfer Instructions
142
Chapter Scheduling Optimizations
143
Instruction Scheduling by Latency
144
145
Loop Unrolling
Loop Unrolling
Partial Loop Unrolling
Complete Loop Unrolling
Example Complete Loop Unrolling
Example Partial Loop Unrolling
Fadd
147
Deriving the Loop Control for Partially Unrolled Loops
148
Inline Functions
149
Additional Recommendations
150
151
Address-Generation Interlocks
Address-Generation Interlocks
152
Movzx and Movsx
153
Pointer Arithmetic in Loops
154
155
156
Pushing Memory Data Directly onto the Stack
157
158
Chapter Integer Optimizations
159
Signed Division Utility
Replacing Division with Multiplication
Multiplication by Reciprocal Division Utility
Unsigned Division Utility
Algorithm Divisors 231 = d
Unsigned Division by Multiplication of Constant
Algorithm Divisors 1 = d 231, Odd d
161
Algorithm Divisors 2 = d
Signed Division by Multiplication of Constant
Simpler Code for Restricted Dividend
Signed Division by
Remainder of Signed Division by 2 or
Signed Division by 2n
Signed Division by -2n
Remainder of Signed Division by 2n or -2n
Alternative Code for Multiplying by a Constant
164
165
166
Guidelines for Repeated String Instructions
Repeated String Instructions
Latency of Repeated String Instructions
167
Use the Largest Possible Operand Size
168
169
Using XOR to Clear Integer Registers
Acceptable
Bit Subtraction
Efficient 64-Bit Integer Arithmetic in 32-Bit Mode
Bit Addition
Bit Negation
Bit Unsigned Division
Bit Right Shift
Bit Multiplication
171
172
Bit Signed Division
173
Bit Unsigned Remainder Computation
174
175
Bit Signed Remainder Computation
176
177
178
179
Integer Version
180
181
Efficient Binary-to-ASCII Decimal Conversion
Binary-to-ASCII Decimal Conversion Retaining Leading Zeros
182
Binary-to-ASCII Decimal Conversion Suppressing Leading Zeros
183
184
185
Unsigned Integer Division
186
187
188
189
Signed Integer Division
Example Code
190
191
Optimizing Integer Division
192
Optimizing with Simd Instructions
193
194
Ensure All Packed Floating-Point Data are Aligned
195
Rationale-Single Precision
196
Rational-Double Precision
197
Use MOVLPx/MOVHPx Instructions for Unaligned Data Access
198
Use Movapd and Movaps Instead of Movupd and Movups
199
200
Loop type Description
201
Double-Precision 32 ⋅ 32 Matrix Multiplication
202
203
204
205
206
207
Passing Data between MMX and 3DNow! Instructions
208
Storing Floating-Point Data in MMX Registers
209
Emms and Femms Usage
210
211
XMM Text Segment
212
213
214
215
Single Precision
Double Precision
Clearing MMX and XMM Registers with XOR Instructions
216
217
218
219
220
221
222
Code below Puts the Floating Point Sign Mask
223
224
225
226
227
Pfpnacc
228
229
230
231
Listing 27 ⋅ 4 Matrix Multiplication SSE
232
XMM3
233
Listing 28 ⋅ 4 Matrix Multiplication 3DNow! Technology
234
235
236
X87 Floating-Point Optimizations
237
Using Multiplication Rather Than Division
238
Achieving Two Floating-Point Operations per Clock Cycle
239
240
241
Align and Pack DirectPath x87 Instructions
242
243
Floating-Point Compare Instructions
244
Using the Fxch Instruction Rather Than FST/FLD Pairs
245
Floating-Point Subexpression Elimination
246
Accumulating Precision-Sensitive Quantities in x87 Registers
247
Avoiding Extended-Precision Data
248
249
Key Microarchitecture Features
251
Processor Block Diagram
Superscalar Processor
AMD Athlon 64 and AMD Opteron Processors Block Diagram
L1 Instruction Cache
253
L1 Instruction Cache Specifications by Processor
Branch-Prediction Table
Instruction Control Unit
L1 Instruction TLB Specifications
Fetch-Decode Unit
Translation-Lookaside Buffer
10 L1 Data Cache
L1 Data TLB Specifications
L2 TLB Specifications
Integer Execution Unit
L1 Data Cache Specifications by Processor
Integer Scheduler
Floating-Point Scheduler
257
Floating-Point Unit
Floating-Point Execution Unit
Load-Store Unit
16 L2 Cache
259
HyperTransport Technology Interface
Buses for AMD Athlon 64 and AMD Opteron Processor
Integrated Memory Controller
HyperTransport Technology
261
Software Optimization Guide for AMD64 Processors
Write-Combining Definitions and Abbreviations
263
264
Programming Details
Write-combining Operations
Write-Combining Completion Events
265
Sending Write-Buffer Data to the System
266
Optimizations
267
268
Appendix C Instruction Latencies
269
Parts of the Instruction Entry
Understanding Instruction Entries
Example Instruction Entry
270
Interpreting Placeholders
271
Interpreting Latencies
272
273
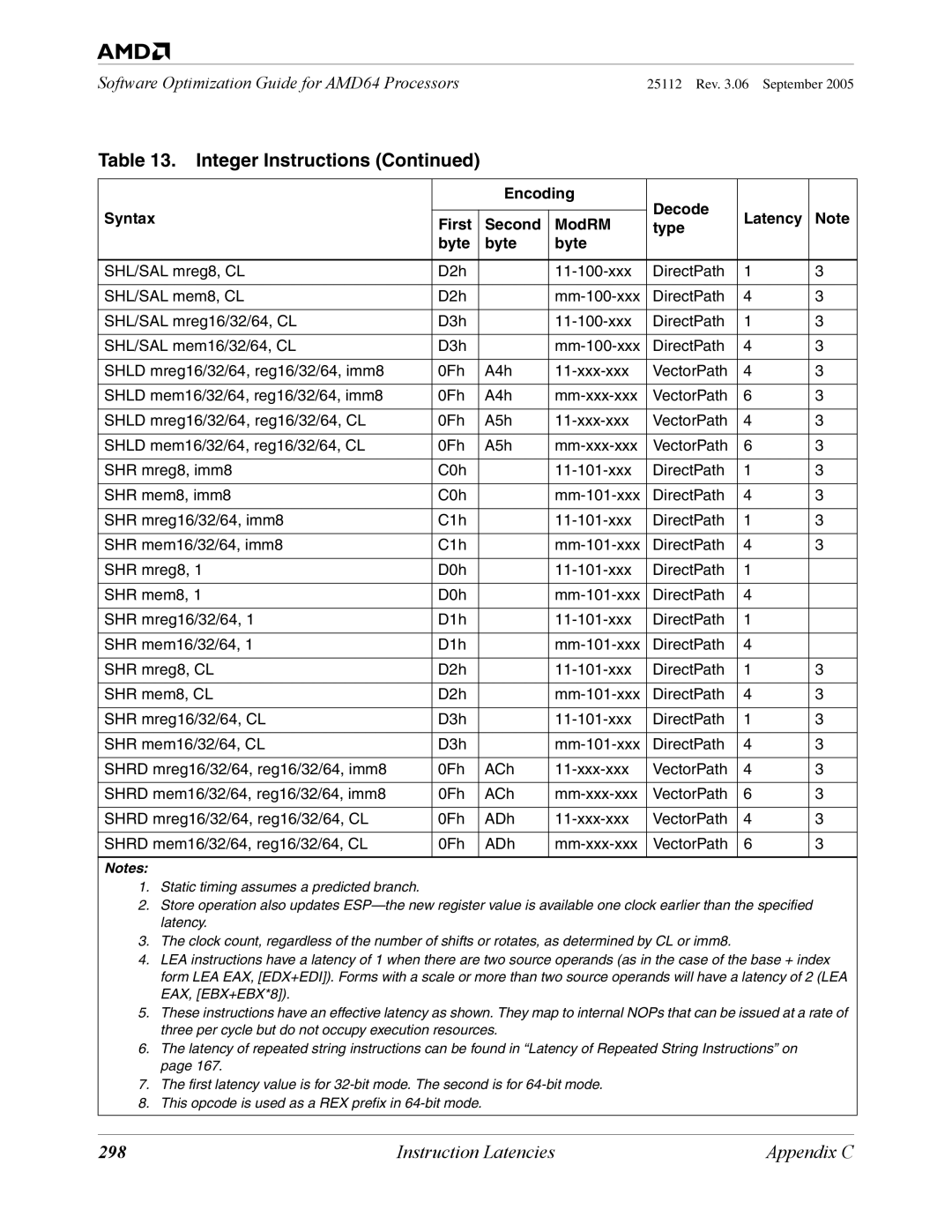
Integer Instructions
Integer Instructions
AAA
274
ADD reg16/32/64, mem16/32/64
275
Bswap EAX/RAX/R8
276
277
278
Mem16/32/64 CMOVNP/CMOVPO reg16/32/64, reg16/32/64
279
CMP reg16/32/64, mreg16/32/64
280
281
282
283
284
JA/JNBE disp16/32
285
Lahf
286
287
Mfence
288
289
NOP Xchg EAX, EAX
290
291
292
Rdpmc
293
Rdmsr
Rdtsc
294
Sahf
295
SBB reg16/32/64, mem16/32/64
296
297
298
STD
299
STC
STI
Sysenter
300
Syscall
Sysexit
301
Xchg AX/EAX/RAX, DI/EDI/RDI/R15
302
Xchg AX/EAX/RAX, SI/ESI/RSI/R14
303
MMX Technology Instructions
MMX Technology Instructions
304
Fmul
305
306
307
X87 Floating-Point Instructions
X87 Floating-Point Instructions
Fadd Fcos
308
Fadd Fcompp
Fdecstp
FADD/FMUL Fstore Finit
309
Fincstp
310
311
312
Fxtract
313
Fxch
FYL2X
314
3DNow! Technology Instructions
3DNow! Technology Instructions
Femms
DNow! Technology Instructions
315
316
3DNow! Technology Extensions
3DNow! Technology Extensions
317
SSE Instructions
SSE Instructions
318
319
320
321
322
Mem64 Prefetchnta mem8 0Fh 18h Mm-000-xxx DirectPath
323
Sfence
324
325
326
SSE2 Instructions
SSE2 Instructions
Fmul Fstore
327
0FH
328
329
Maskmovdqu
330
Fadd Fmul Fstore
331
332
333
Fadd Fmul
334
335
336
337
338
Fmul Punpckhdq
339
Fmul Punpckhbw
340
341
342
SSE3 Instructions
SSE3 Instructions
343
344
Fast-Write Optimizations
345
Fast-Write Optimizations for Graphics-Engine Programming
346
Cacheable-Memory Command Structure
347
348
Fast-Write Optimizations for Video-Memory Copies
349
350
Memory Optimizations
351
Northbridge Command Flow
352
353
Optimizations for Texture-Map Copies to AGP Memory
Optimizations for Vertex-Geometry Copies to AGP Memory
354
355
Types of XMM-Register Data
Types of SSE and SSE2 Instructions
Half-Register Operations
356
357
Zeroing Out an XMM Register
Clearing XMM Registers
358
Reuse of Dead Registers
359
Moving Data Between XMM Registers and GPRs
360
Saving and Restoring Registers of Unknown Format
361
SSE and SSE2 Copy Loops
362
Explicit Load Instructions
363
364
Data Conversion
Converting Scalar Values
365
Converting Vector Values
Converting Directly from Memory
INT GPR FPS
366
Numerics
367
368 Index