191
Complex Samples Logistic Regression
What constitutes a “good” R2 value varies between different areas of application. While these statistics can be suggestive on their own, they are most useful when comparing competing models for the same data. The model with the largest R2 statistic is “best” according to this measure.
Classification
Figure
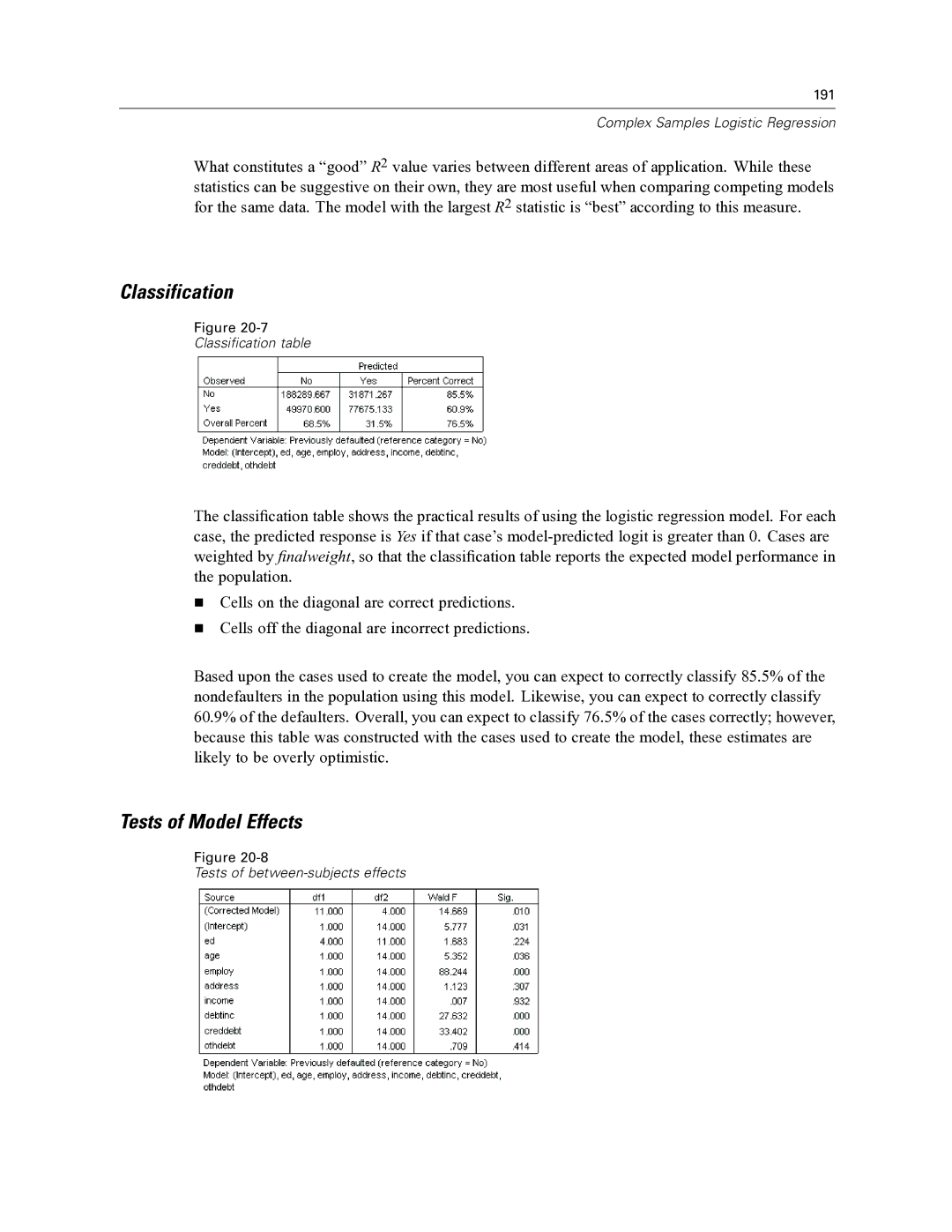
Classification table
The classification table shows the practical results of using the logistic regression model. For each case, the predicted response is Yes if that case’s
Cells on the diagonal are correct predictions.
Cells off the diagonal are incorrect predictions.
Based upon the cases used to create the model, you can expect to correctly classify 85.5% of the nondefaulters in the population using this model. Likewise, you can expect to correctly classify 60.9% of the defaulters. Overall, you can expect to classify 76.5% of the cases correctly; however, because this table was constructed with the cases used to create the model, these estimates are likely to be overly optimistic.
Tests of Model Effects
Figure
Tests of