5.5.3.1Support for NUMA servers
NUMA is an architecture wherein the memory access time for different regions of memory from a given processor varies according to the nodal distance of the memory region from the processor. Each region of memory, to which access times are the same from any CPU, is called a node. The NUMA architecture surpasses the scalability limits of SMP (Symmetric
With SMP, all memory accesses are posted to the same shared memory bus. This works fine for a relatively small number of CPUs, but there is a problem with hundreds of CPUs competing for access to this shared memory bus. NUMA alleviates these bottlenecks by limiting the number of CPUs on any one memory bus and connecting the various nodes by means of a
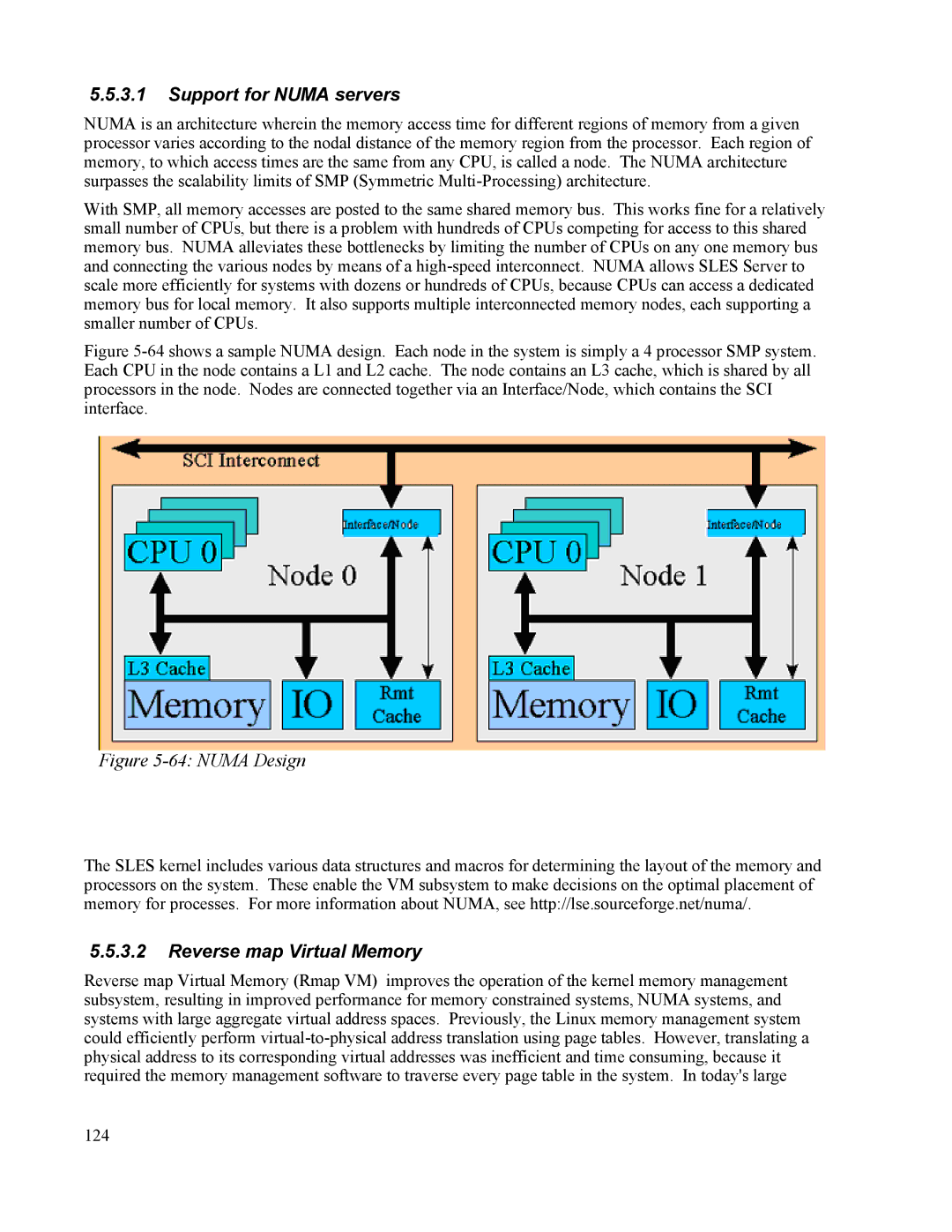
Figure 5-64 shows a sample NUMA design. Each node in the system is simply a 4 processor SMP system. Each CPU in the node contains a L1 and L2 cache. The node contains an L3 cache, which is shared by all processors in the node. Nodes are connected together via an Interface/Node, which contains the SCI interface.
Figure 5-64: NUMA Design
The SLES kernel includes various data structures and macros for determining the layout of the memory and processors on the system. These enable the VM subsystem to make decisions on the optimal placement of memory for processes. For more information about NUMA, see http://lse.sourceforge.net/numa/.
5.5.3.2Reverse map Virtual Memory
Reverse map Virtual Memory (Rmap VM) improves the operation of the kernel memory management subsystem, resulting in improved performance for memory constrained systems, NUMA systems, and systems with large aggregate virtual address spaces. Previously, the Linux memory management system could efficiently perform
124