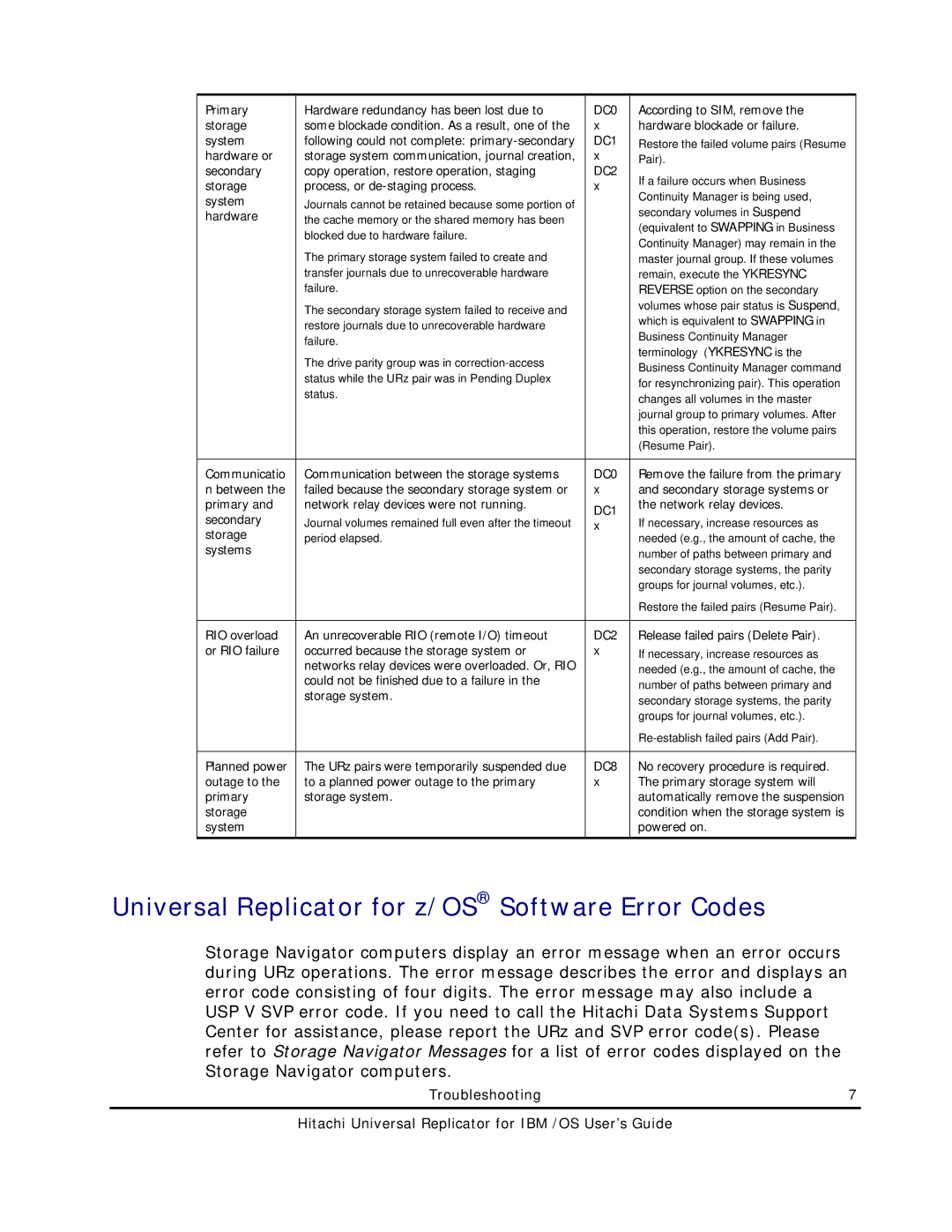
Primary | Hardware redundancy has been lost due to | DC0 | According to SIM, remove the | |
storage | some blockade condition. As a result, one of the | x | hardware blockade or failure. | |
system | following could not complete: | DC1 | Restore the failed volume pairs (Resume | |
hardware or | storage system communication, journal creation, | x | Pair). | |
secondary | copy operation, restore operation, staging | DC2 | If a failure occurs when Business | |
storage | process, or | x | ||
system | Journals cannot be retained because some portion of |
| Continuity Manager is being used, | |
| secondary volumes in Suspend | |||
hardware | the cache memory or the shared memory has been |
| ||
| (equivalent to SWAPPING in Business | |||
| blocked due to hardware failure. |
| ||
|
| Continuity Manager) may remain in the | ||
| The primary storage system failed to create and |
| ||
|
| master journal group. If these volumes | ||
| transfer journals due to unrecoverable hardware |
| remain, execute the YKRESYNC | |
| failure. |
| REVERSE option on the secondary | |
| The secondary storage system failed to receive and |
| volumes whose pair status is Suspend, | |
| restore journals due to unrecoverable hardware |
| which is equivalent to SWAPPING in | |
| failure. |
| Business Continuity Manager | |
| The drive parity group was in |
| terminology (YKRESYNC is the | |
|
| Business Continuity Manager command | ||
| status while the URz pair was in Pending Duplex |
| ||
|
| for resynchronizing pair). This operation | ||
| status. |
| ||
|
| changes all volumes in the master | ||
|
|
| journal group to primary volumes. After | |
|
|
| this operation, restore the volume pairs | |
|
|
| (Resume Pair). | |
|
|
|
| |
Communicatio | Communication between the storage systems | DC0 | Remove the failure from the primary | |
n between the | failed because the secondary storage system or | x | and secondary storage systems or | |
primary and | network relay devices were not running. | DC1 | the network relay devices. | |
secondary | Journal volumes remained full even after the timeout | If necessary, increase resources as | ||
x | ||||
storage | period elapsed. |
| needed (e.g., the amount of cache, the | |
systems |
|
| number of paths between primary and | |
|
|
| secondary storage systems, the parity | |
|
|
| groups for journal volumes, etc.). | |
|
|
| Restore the failed pairs (Resume Pair). | |
|
|
|
| |
RIO overload | An unrecoverable RIO (remote I/O) timeout | DC2 | Release failed pairs (Delete Pair). | |
or RIO failure | occurred because the storage system or | x | If necessary, increase resources as | |
| networks relay devices were overloaded. Or, RIO |
| needed (e.g., the amount of cache, the | |
| could not be finished due to a failure in the |
| number of paths between primary and | |
| storage system. |
| secondary storage systems, the parity | |
|
|
| groups for journal volumes, etc.). | |
|
|
|
| |
|
|
|
| |
Planned power | The URz pairs were temporarily suspended due | DC8 | No recovery procedure is required. | |
outage to the | to a planned power outage to the primary | x | The primary storage system will | |
primary | storage system. |
| automatically remove the suspension | |
storage |
|
| condition when the storage system is | |
system |
|
| powered on. | |
|
|
|
|
Universal Replicator for z/OS® Software Error Codes
Storage Navigator computers display an error message when an error occurs during URz operations. The error message describes the error and displays an error code consisting of four digits. The error message may also include a USP V SVP error code. If you need to call the Hitachi Data Systems Support Center for assistance, please report the URz and SVP error code(s). Please refer to Storage Navigator Messages for a list of error codes displayed on the Storage Navigator computers.
Troubleshooting | 7 |