PERFORMANCE CONSIDERATIONS
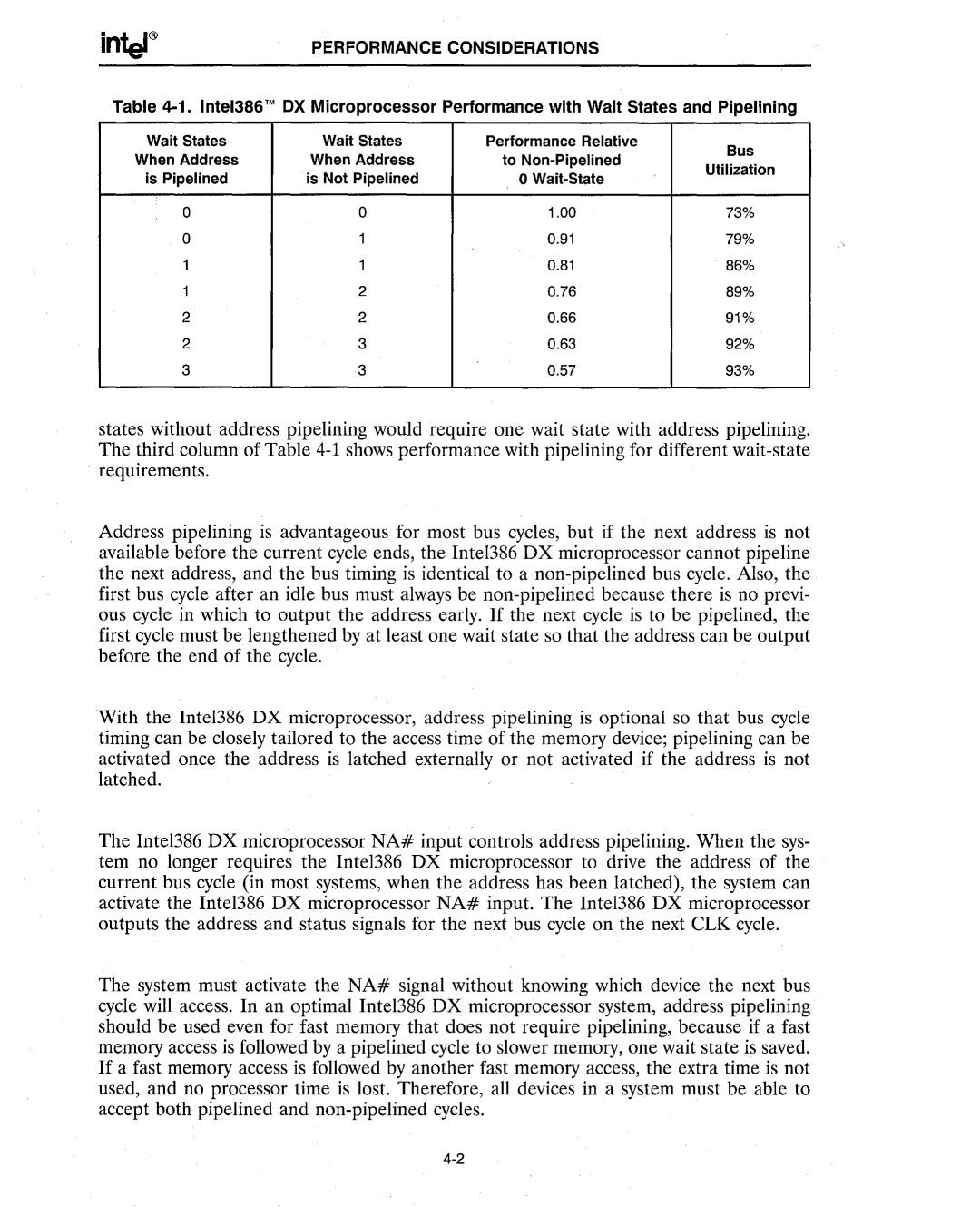
Table
Wait States | Wait States | Performance Relative | Bus | |
When Address | When Address | to | ||
Utilization | ||||
is Pipelined | is Not Pipelined | o | ||
| ||||
0 | 0 | 1.00 | 73% | |
0 | 1 | 0.91 | 79% | |
1 | 1 | 0.81 | 86% | |
1 | 2 | 0.76 | 89% | |
2 | 2 | 0.66 | 91% | |
2 | 3 | 0.63 | 92% | |
3 | 3 | 0.57 | 93% |
states without address pipelining would require one wait state with address pipelining. The third column of Table
Address pipelining is advantageous for most bus cycles, but if the next address is not available before the current cycle ends, the Intel386 OX microprocessor cannot pipeline the next address, and the bus timing is identical to a
With the Inte1386 OX microprocessor, address pipelining is optional so that bus cycle timing can be closely tailored to the access time of the memory device; pipelining can be activated once the address is latched externally or not activated if the address is not latched.
The Intel386 OX microprocessor NA# input controls address pipelining. When the sys- tem no longer requires the Inte1386 OX microprocessor to drive the address of the current bus cycle (in most systems, when the address has been latched), the system can activate the Inte1386 OX microprocessor NA# input. The Intel386 OX microprocessor outputs the address and status signals for the next bus cycle on the next eLK cycle.
The system must activate the NA# signal without knowing which device the next bus cycle will access. In an optimal Intel386 OX microprocessor system, address pipelining should be used even for fast memory that does not require pipelining, because if a fast memory access is followed by a pipelined cycle to slower memory, one wait state is saved. If a fast memory access is followed by another fast memory access, the extra time is not used, and no processor time is lost. Therefore, all devices in a system must be able to accept both pipelined and